论文简述
YOLOv1
一个实时目标检测模型,因对整张图片进行检测(Unified Detection),使用卷积进行滑动窗口的实现,大大提高了对象检测的效率。因为第二段是论文的核心内容,因此本文将YOLOv1的第二段进行主观式理解与翻译,如有不对还请指正。你可以在这里下载
理解式翻译
以下为论文原文翻译
2.统一检测
Ⅰ.
- 将目标检测的分离组件统一到一个神经网络
- 使用整张图片的特征预测bounding box(以下简称bbox)
- 同时预测一张照片的所有bbox和类别
- 此网络考虑整张图片和所有目标
- 端到端训练、实时、高平均精度
Ⅱ.
- 将图片分成$S \times S$的网格
- 如果对象的中心点落在一个cell中,这个cell就负责检测这个目标
Ⅲ.
- 每个cell预测B个bbox和这些bbox的置信度
- 置信度反映了:模型有多确信box包含一个对象;box预测得有多精确
- 定义置信度$=Pr(Object) \ast IOU_{pred}^{truth}$
- cell中没有对象时,置信度为0
- 否则置信度=介于预测box与真实值之间的IOU
Ⅳ.
- 每个bbox包含五个预测值:$x,y,w,h,confidence$
- $(x,y)$坐标代表box相对于cell边界的中心点
- 相对于整个图像预测宽度和高度
- 最后,置信度代表介于预测box与真实box之间的IOU
Ⅴ.
- 每个cell预测了C个条件类别概率,$Pr(Class_{i} \mid Object)$
- 这些概率是在cell包含一个对象的条件下成立的
- 只预测每个cell中国的类别可能性的一个集合,而不管B个box的数量
Ⅵ.
- 测试时,将条件类别概率×每个box的置信度预测值,从而得到了每个box特定类别的置信度:
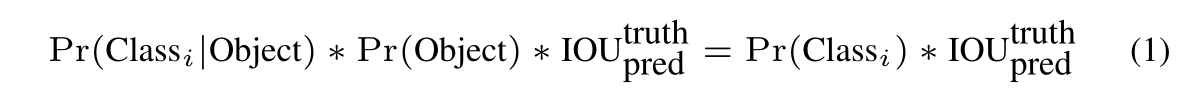
- 这些置信度编码了:在box中出现某个类别的可能性;预测box有多适合目标
Ⅶ.
- 为了在PASCAL VOC(以下简称PV)上测试YOLO,令S=7,B=2,PV有20个类别,所以C=20,最终预测值是一个7×7×30的张量
2.1 网络设计
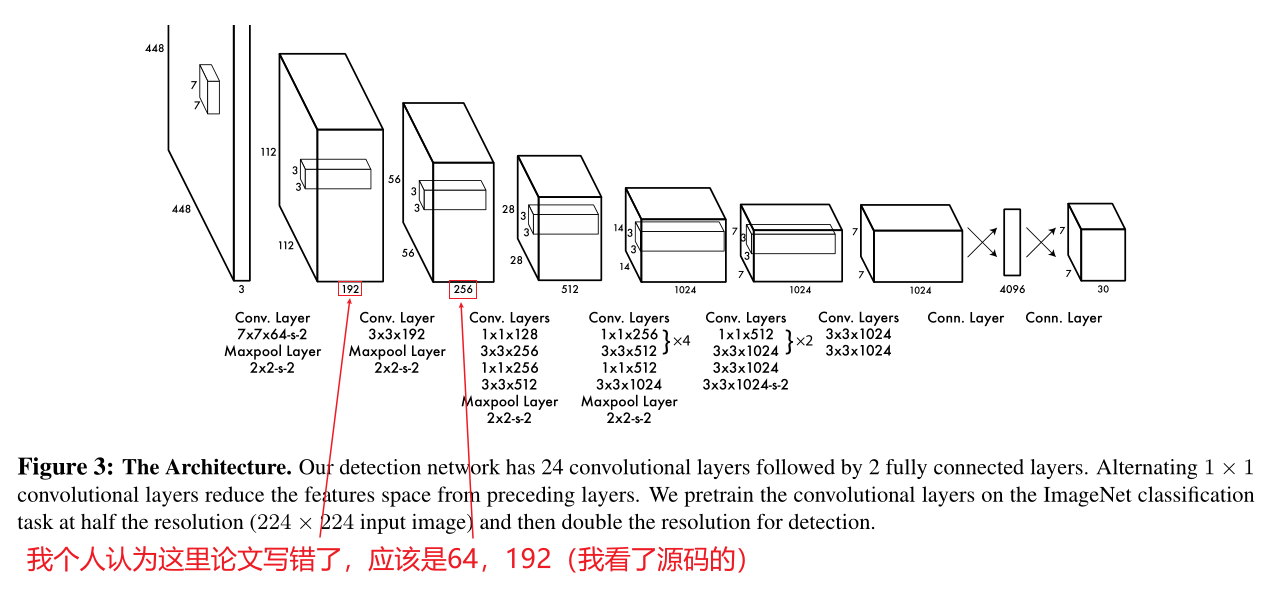
Ⅰ.
- 使用卷积神经网络实现这个模型并在PV数据集上评估
- 初始化卷积层,从图片中提取特征,然后使用全连接层预测输出可能性和坐标
Ⅱ.
- 网络结构受GoogLeNet启发
- 有24层卷积层和2层全连接层
- 为了代替GoogLeNet中的inception模块,使用了1×1reduction层和3×3卷积层
Ⅲ.
- 训练了YOLO的更快版本,为了达到更快的边界预测
- Fast YOLO使用了更少的卷积层(9层而非24层)以及层中更少的过滤器
- 所有的训练和测试参数介于YOLO与Fast YOLO之间
2.2 训练
Ⅰ.
- 在ImageNet上预训练了卷积层
- 为了预训练使用了前20层卷积+一个平均池化层+一个全连接层
- 训练大约一周,在ImageNet 2012验证集中是top5,88%的准确率
- 使用Darknet框架做所有的训练和推导
Ⅱ.
- 然后将模型转化为执行检测
- Ren等证明预训练卷积层和全连接层可提升性能
- 以此为鉴,我们加了4层卷积层和2层全连接层,并随机初始化权重
- 检测需要更细粒度的视觉信息,所以将分辨率224×224 -> 448×448
Ⅲ.
- 最后一层能同时预测类别概率和bbox坐标
- 用图像的宽高归一化bbox的宽高,使它们的取值为[0,1]
- 将bbox的(x,y)坐标参数化为特定网格单元位置的偏移量,使其取值为[0,1]
Ⅳ.
- 最后一层使用线性激活函数,其他层使用LeakyReLu
Ⅴ.
- 优化模型的平方和误差输出
- 使用平方和误差是因为其易于优化,然而它不能完美校准最大平均精度
- 它将定位误差等价为分类误差,这不太理想
- 而且在每张图片的cell中,很多都不包含对象
- 这使这些cell的置信度趋向0,经常会掩盖确实包含对象的cell的梯度
- 这导致模型不稳定,造成训练过早发生偏离
Ⅵ.
- 为了进行补救,增加了来自bbox座标预测的损失;并减少了来自不包含对象的box的置信度损失
- 使用两个参数$\lambda _{coord}$,$\lambda _{noobj}$来完成它
- 设置$\lambda _{coord}=5$,$\lambda _{noobj}=0.5$
Ⅶ.
- 平方和误差也平等地权衡了大box和小box的误差
- 误差指标应该反映大box的小误差,而不是小box的
- 为尽量解决这个问题,预测bbox宽高的平方根来取代宽高
Ⅷ.
- YOLO在每个cell预测了很多bbox
- 在训练时,只想要一个bbox预测来负责每个目标对象
- 我们分配一个预测框负责预测一个对象,基于这个对象的预测拥有和真实值的最大当前IOU
- 这导致bbox预测框
- 每个预测框都能更好的预测某些尺寸,长宽比或对象类别,从而提高整体召回率
Ⅸ.
训练期间优化了下面这个复杂的损失函数:

其中$1_{i}^{obj}$表示对象是否出现在第i个cell中,$1_{ij}^{obj}$表示在第i个cell中第j个bbox预测框负责那次预测。
Ⅹ.
- 注意:如果cell中存在目标,损失函数只会惩罚分类错误(之前条件类别概率讨论过)
- 如果预测框负责真实值的box(在cell中拥有任意预测框的最高IOU),它也会惩罚bbox的座标误差
Ⅺ.
- 在PV2007和2012训练和验证集上训练网络135个epoch
- 在2012年的数据上测试时,也包括VOC2007测试数据进行训练
- 训练时,batch_size=64,momentum=0.9,decay=0.0005
Ⅻ.
- 学习率变化如下:
- 第一个epoch,我们将学习率从$10^{-3}$缓慢提升到$10^{-2}$
- 如果以高学习率开始,由于梯度不稳定,我们的模型会发散
- 用$10^{-2}$训练75个epoch,$10^{-3}$训练30个epoch,最后$10^{-4}$训练30个epoch
XIII.
- 为了避免过拟合,使用dropout和数据扩充
- dropout层中,rate=0.5,位于第一个连接层后,防止层与层之间的共同适应
- 对于数据扩充,引入随机缩放和至多20%原始图像的大小变换
- 在HSV颜色空间中随即调整1.5倍曝光和饱和度
2.3 推论
Ⅰ.
- 就像训练,预测图像的检测只需要一次网络评估
- 在PV上,网络在每张图片上可预测98个bbox和每个box的类别概率
- 不像基于分类器的方法,因为YOLO只需一次网络评估,所以在测试时速度特别快
Ⅱ.
- 网络设计在bbox预测中强制空间分集
- 通常,很明显一个对象落到一个cell中,并且网络只为每个对象预测一个box
- 然而,一些大目标或多个cell附近的对象能够被很好的定位
- 非极大值抑制可避免多次检测
- 对R-CNN或DPM来说,性能不是最重要的,但极大值抑制可提高2%-3%的mAP
2.4 YOLO的不足
Ⅰ.
- YOLO对bbox预测施加了强大的空间约束,因为每个cell只能预测连个box和一个类别
- 这种空间约束限制了模型可以预测的附近物体的数量
- 模型不擅长处理成组的小目标,例如成群的鸟
Ⅱ.
- 因为模型从数据中学习预测bbox,它很难推广到新的、不同长宽比或配置的目标
- 模型使用相对粗糙的特征预测bbox,因为我们的结构拥有从输出图像获得的下采样层
Ⅲ.
- 最后,虽然我们近似检测性能的损失函数,但我们的损失函数同等对待小box与大box的误差
- 大box中的小误差通常是良性的,但小box中的小误差对IOU有更大的影响
- 误差的主要来源是定位错误