Why
提高查询性能
What
索引是存储引擎用于快速找到记录的一种数据结构
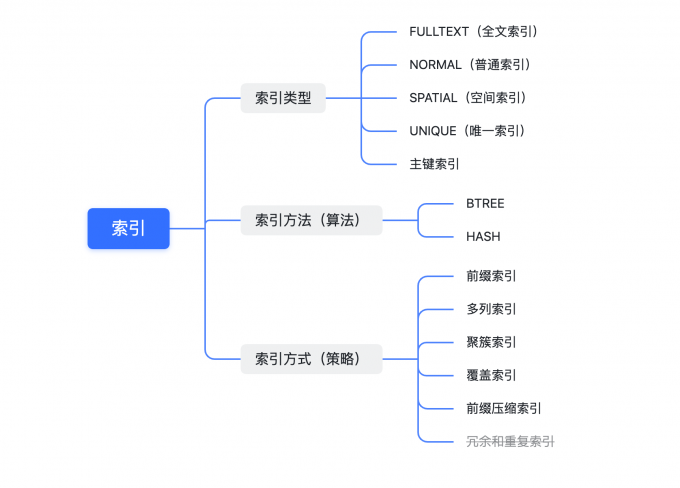
索引类型
全文索引
一种特殊类型的索引,它查找的是文本中的关键词,而不是直接比较索引中的值。全文索引更类似于搜索引擎做的事情,而不是简单的WHERE条件匹配。
普通索引
空间索引
为空间数据(点线面)类型字段建立的索引
唯一索引
唯一索引表明当前字段内的值不重复;唯一索引不一定是主键索引,一张表中可以有多个唯一索引;唯一索引允许字段的值为null
主键索引
特殊的唯一索引,逻辑键,不真实存在;主键索引不允许字段值为null,即不允许主键(id)为空
索引方法(算法)
BTREE
使用B-Tree数据结构来存储数据,InnoDB使用的是B+Tree,在一个多列BTREE索引中,索引列的顺序意味着索引首先按照最左列进行排序,然后是第二列。
HASH
InnoDB支持Hash索引,但是InnoDB中Hash索引的创建由存储引擎自动优化创建,不能人为干预是否为表创建Hash索引
索引方式(策略)
前缀索引
索引开始的部分字符,节约索引空间,提高索引效率
索引的选择性:选择足够长的前缀以保证较高的选择性(比如只选择前七个字符就能确定唯一或唯二的数据)
多列索引
MySQL5.0+ 引入索引合并策略,使用多个单列索引来指定唯一行
这是一种优化策略,多数情况下表名原来的单列索引没有建好,而导致无法确定唯一行
多列索引是有顺序的,这个顺序非常重要
聚簇索引
聚簇索引不是一种单独的索引类型,而是一种数据存储方式,InnoDB的聚簇索引实际上在同一个数据结构中保存了BTREE索引和数据行
数据行实际上存储在索引的叶子页
因为无法把数据行存放在两个不同的地方,所以一个表只能有一个聚簇索引。
覆盖索引
包含(覆盖)所有需要查询的字段的值而无需回表
由于InnoDB的聚簇索引,覆盖索引对InnoDB表特别有用。InnoDB的二级索引在叶子节点中保存了行的主键值,所以如果二级主键能够覆盖查询,则可以避免对主键索引的二次查询
前缀压缩索引
MyISAM存储引擎;减小索引的大小,从而让更多的索引放入内存中
索引不是“银弹”
只有当某些字段需要提高查询性能时,并且使用索引带来的好处大于额外工作,这样才有必要使用索引。小表全表扫描,大表再建索引。
索引不是只有好处的,添加索引会使数据写入变慢,因为还得更新索引。
实例分析
经过上边的一通分析,感觉索引这个概念还是有些遥不可及,其实最简单的往往是最常用的,以下我将针对我们的项目进行举例分析。
首先最常用的索引类型是普通索引和唯一索引,空间索引常用于GIS(地理信息系统),全文索引更类似于搜索引擎做的事,我们会用ES做全局搜索
例一:
1 | CREATE TABLE `lc_object` ( |
这是咱们系统里的lc_object表,表中的id就是主键,tenant_id就是手动建立的普通索引KEY,可以看到主键索引PRIMARY KEY也是一种KEY,一种特殊的唯一索引。
例二:
1 | CREATE TABLE `bs_holiday` ( |
这是咱们系统里的lc_holiday表,表中的id就是主键,同时主键建了唯一索引UNIQUE KEY
不过我这里有些小小见解,主键其实已经是一种特殊的唯一索引了,没有必要在给他建个唯一索引
书接例一:
我们使用的普通索引都是BTREE索引,我们来探索一下这个普通索引是如何快速查询的
执行这条查询语句:SELECT id,name FROM lc_object WHERE tenant_id="1453698";
我们这里假设对于tenant_id的索引使用前缀索引,只取前两位
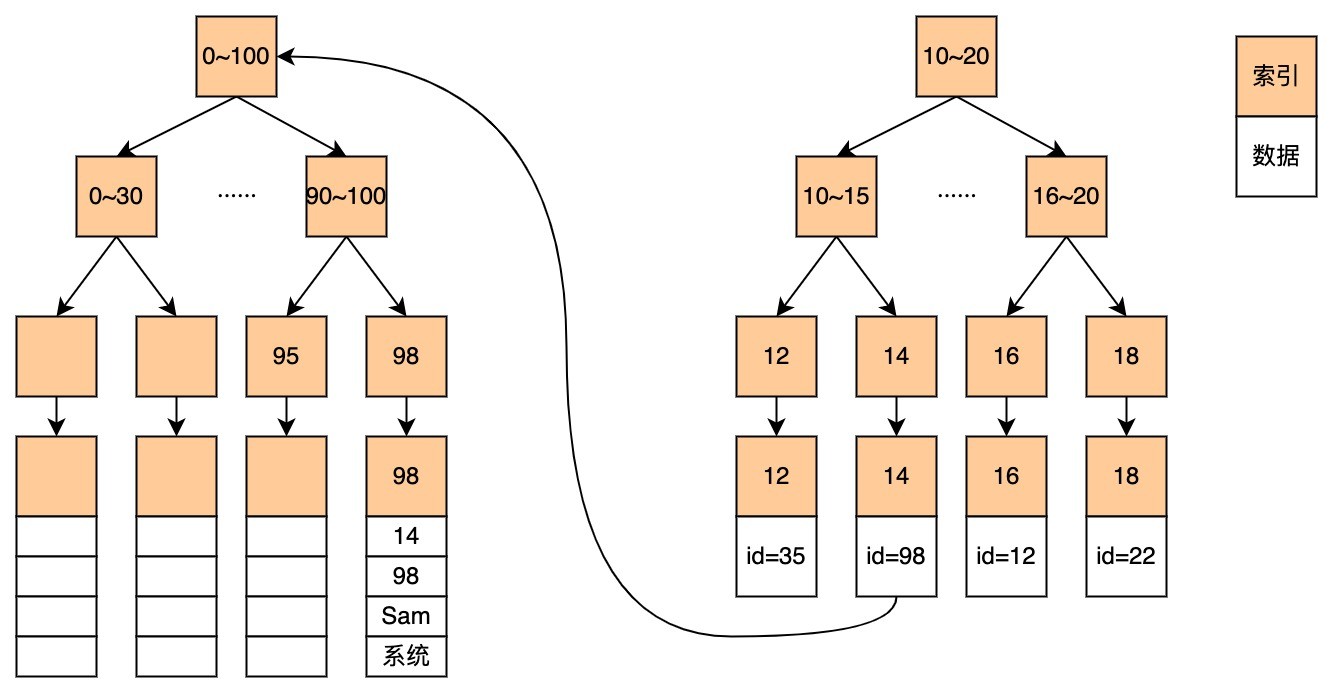
使用BTREE数据结构实现的的普通索引,都是先使用建立索引的字段与主键建立联系,从索引中找到id后,需要进行一次回表查询,再通过id查询到具体数据
那假如我们现在要使用聚簇索引进行优化,情况会是怎样呢?
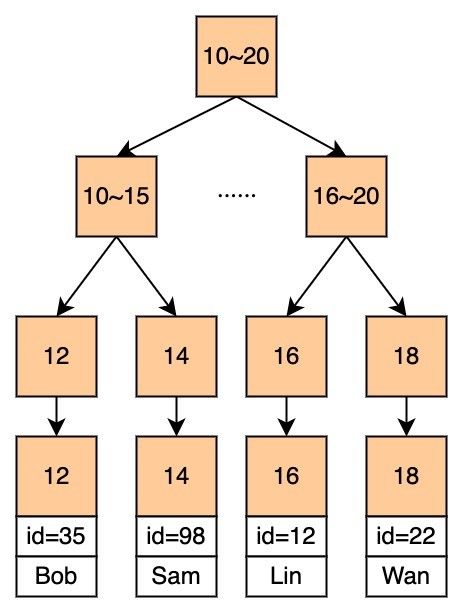
此时,id和name都保存在了叶子节点中,我们只需要查询一次就能找到数据了,不需要再次回表查询,这样就提高了效率。
另外再说一下,如果我们在这里还对id建立了索引,此时被建立索引的字段(id、name)和我们要SELECT的字段是一致的,此时就是覆盖索引,即要查询的字段恰好都建立了索引